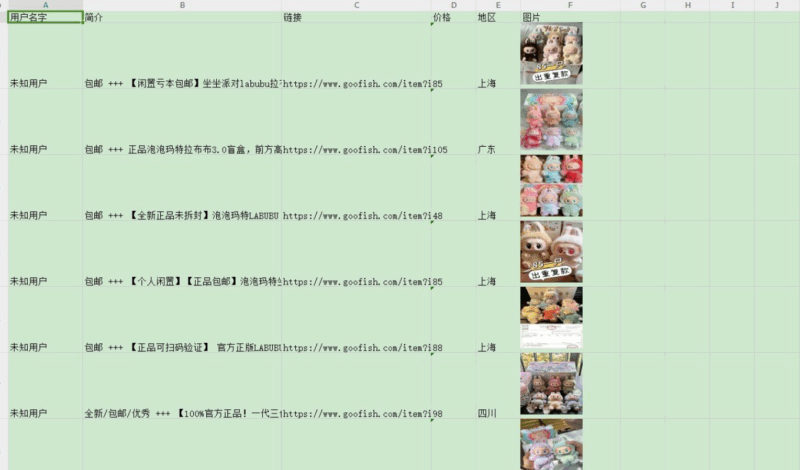


闲鱼多线程商品爬虫程序(带GUI界面)
功能特点:
- 多线程爬取提高效率
- 图形界面操作更友好
- 自动保存和加载Cookie
- 支持下载商品图片并插入到Excel
- 修复了.mpo等特殊图片格式导致的保存失败问题
- 实时日志显示
注意事项:
- 本程序仅用于学习交流,请勿用于商业或非法用途
- 请遵守网站robots协议,合理控制请求频率
import requests
import time
import hashlib
import threading
import queue
import json
import os
from openpyxl import Workbook
from openpyxl.drawing.image import Image
from openpyxl.utils import get_column_letter
import tkinter as tk
from tkinter import ttk, messagebox, scrolledtext
from datetime import datetime
# 常量配置
API_URL = "https://h5api.m.goofish.com/h5/mtop.taobao.idlemtopsearch.pc.search/1.0/"
APP_KEY = "34839810"
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0"
REQUEST_DELAY = 1.5 # 请求间隔时间(秒)
COOKIE_FILE = "xianyu_cookie.json" # Cookie存储文件
MAX_WORKERS = 5 # 最大工作线程数
IMAGE_FOLDER = "xianyu_images" # 图片保存文件夹
SUPPORTED_IMAGE_FORMATS = ['jpg', 'jpeg', 'png', 'gif', 'bmp'] # 支持的图片格式
class XianyuSpiderGUI:
def __init__(self, root):
self.root = root
self.root.title("闲鱼商品爬虫 v2.1(修复图片格式问题)")
self.root.geometry("800x600")
self.root.resizable(True, True)
# 创建日志队列
self.log_queue = queue.Queue()
# 创建状态变量
self.is_running = False
self.cookie = ""
self.token = ""
# 确保图片文件夹存在
if not os.path.exists(IMAGE_FOLDER):
os.makedirs(IMAGE_FOLDER)
# 加载保存的Cookie
self.load_cookie()
# 创建界面
self.create_widgets()
# 启动日志更新线程
threading.Thread(target=self.update_log, daemon=True).start()
def create_widgets(self):
# 创建主框架
main_frame = ttk.Frame(self.root, padding="10")
main_frame.pack(fill=tk.BOTH, expand=True)
# 输入区域
input_frame = ttk.LabelFrame(main_frame, text="爬取设置", padding="10")
input_frame.pack(fill=tk.X, pady=(0, 10))
# Cookie输入
ttk.Label(input_frame, text="Cookie:").grid(row=0, column=0, sticky=tk.W, pady=2)
self.cookie_var = tk.StringVar(value=self.cookie)
self.cookie_entry = ttk.Entry(input_frame, textvariable=self.cookie_var, width=80)
self.cookie_entry.grid(row=0, column=1, sticky=tk.EW, padx=(5, 0), pady=2)
# 关键词输入
ttk.Label(input_frame, text="关键词:").grid(row=1, column=0, sticky=tk.W, pady=2)
self.keyword_var = tk.StringVar()
self.keyword_entry = ttk.Entry(input_frame, textvariable=self.keyword_var, width=30)
self.keyword_entry.grid(row=1, column=1, sticky=tk.W, padx=(5, 0), pady=2)
# 页数设置
ttk.Label(input_frame, text="爬取页数:").grid(row=2, column=0, sticky=tk.W, pady=2)
self.page_var = tk.StringVar(value="1")
self.page_entry = ttk.Entry(input_frame, textvariable=self.page_var, width=10)
self.page_entry.grid(row=2, column=1, sticky=tk.W, padx=(5, 0), pady=2)
# 线程控制
ttk.Label(input_frame, text="线程数:").grid(row=3, column=0, sticky=tk.W, pady=2)
self.thread_var = tk.StringVar(value=str(MAX_WORKERS))
self.thread_combo = ttk.Combobox(input_frame, textvariable=self.thread_var, width=5, state="readonly")
self.thread_combo['values'] = tuple(str(i) for i in range(1, MAX_WORKERS + 1))
self.thread_combo.grid(row=3, column=1, sticky=tk.W, padx=(5, 0), pady=2)
# 按钮区域
btn_frame = ttk.Frame(main_frame)
btn_frame.pack(fill=tk.X, pady=(0, 10))
self.start_btn = ttk.Button(btn_frame, text="开始爬取", command=self.start_crawling)
self.start_btn.pack(side=tk.LEFT, padx=(0, 10))
self.stop_btn = ttk.Button(btn_frame, text="停止", command=self.stop_crawling, state=tk.DISABLED)
self.stop_btn.pack(side=tk.LEFT)
ttk.Button(btn_frame, text="清除日志", command=self.clear_log).pack(side=tk.RIGHT)
ttk.Button(btn_frame, text="保存Cookie", command=self.save_cookie).pack(side=tk.RIGHT, padx=(0, 10))
# 日志区域
log_frame = ttk.LabelFrame(main_frame, text="日志信息", padding="10")
log_frame.pack(fill=tk.BOTH, expand=True)
self.log_text = scrolledtext.ScrolledText(log_frame, wrap=tk.WORD, state=tk.DISABLED)
self.log_text.pack(fill=tk.BOTH, expand=True)
# 状态栏
self.status_var = tk.StringVar(value="就绪")
status_bar = ttk.Label(self.root, textvariable=self.status_var, relief=tk.SUNKEN, anchor=tk.W)
status_bar.pack(side=tk.BOTTOM, fill=tk.X)
def log_message(self, message):
"""将消息添加到日志队列"""
timestamp = datetime.now().strftime("%H:%M:%S")
self.log_queue.put(f"[{timestamp}] {message}")
def update_log(self):
"""定期检查并更新日志显示"""
try:
while True:
# 从队列获取所有可用消息
messages = []
while not self.log_queue.empty():
messages.append(self.log_queue.get_nowait())
if messages:
self.log_text.config(state=tk.NORMAL)
for msg in messages:
self.log_text.insert(tk.END, msg + "\n")
self.log_text.config(state=tk.DISABLED)
self.log_text.yview(tk.END)
time.sleep(0.1)
except Exception as e:
print(f"日志更新线程错误: {e}")
def clear_log(self):
"""清除日志内容"""
self.log_text.config(state=tk.NORMAL)
self.log_text.delete(1.0, tk.END)
self.log_text.config(state=tk.DISABLED)
def load_cookie(self):
"""从文件加载Cookie"""
try:
if os.path.exists(COOKIE_FILE):
with open(COOKIE_FILE, 'r', encoding='utf-8') as f:
data = json.load(f)
self.cookie = data.get('cookie', '')
self.log_message(f"已加载保存的Cookie")
except Exception as e:
self.log_message(f"⚠️ 加载Cookie失败: {e}")
def save_cookie(self):
"""保存Cookie到文件"""
self.cookie = self.cookie_var.get().strip()
if not self.cookie:
messagebox.showwarning("警告", "Cookie不能为空")
return
try:
with open(COOKIE_FILE, 'w', encoding='utf-8') as f:
json.dump({'cookie': self.cookie}, f, ensure_ascii=False, indent=2)
self.log_message("✅ Cookie保存成功")
except Exception as e:
self.log_message(f"❌ 保存Cookie失败: {e}")
def extract_token(self):
"""从cookie中提取token"""
cookie = self.cookie_var.get().strip()
if not cookie:
self.log_message("❌ Cookie不能为空")
return None
try:
# 查找_m_h5_tk在cookie中的位置
if "_m_h5_tk=" not in cookie:
self.log_message("❌ Cookie中缺少_m_h5_tk值")
return None
start_idx = cookie.find("_m_h5_tk=") + len("_m_h5_tk=")
end_idx = cookie.find(";", start_idx)
if end_idx == -1:
end_idx = len(cookie)
m_h5_tk_value = cookie[start_idx:end_idx]
token = m_h5_tk_value.split('_')[0]
return token
except Exception as e:
self.log_message(f"❌ 提取Token失败: {e}")
return None
def validate_inputs(self):
"""验证用户输入"""
# 验证Cookie
self.cookie = self.cookie_var.get().strip()
if not self.cookie:
messagebox.showwarning("警告", "Cookie不能为空")
return False
# 提取token
self.token = self.extract_token()
if not self.token:
return False
# 验证关键词
keyword = self.keyword_var.get().strip()
if not keyword:
messagebox.showwarning("警告", "关键词不能为空")
return False
# 验证页数
try:
pages = int(self.page_var.get())
if pages <= 0:
messagebox.showwarning("警告", "页数必须是正整数")
return False
except ValueError:
messagebox.showwarning("警告", "页数必须是数字")
return False
# 验证线程数
try:
threads = int(self.thread_var.get())
if threads <= 0 or threads > MAX_WORKERS:
messagebox.showwarning("警告", f"线程数必须在1-{MAX_WORKERS}之间")
return False
except ValueError:
messagebox.showwarning("警告", "线程数必须是数字")
return False
return True
def start_crawling(self):
"""开始爬取"""
if self.is_running:
return
if not self.validate_inputs():
return
# 更新界面状态
self.is_running = True
self.start_btn.config(state=tk.DISABLED)
self.stop_btn.config(state=tk.NORMAL)
self.status_var.set("运行中...")
# 获取参数
keyword = self.keyword_var.get().strip()
pages = int(self.page_var.get())
threads = int(self.thread_var.get())
# 创建任务队列
self.task_queue = queue.Queue()
for page in range(1, pages + 1):
self.task_queue.put(page)
# 创建结果列表
self.results = []
self.failed_pages = []
# 创建并启动工作线程
self.workers = []
for i in range(threads):
worker = threading.Thread(target=self.worker_task, args=(keyword,))
worker.daemon = True
worker.start()
self.workers.append(worker)
self.log_message(f"启动工作线程 #{i + 1}")
# 启动监视线程
threading.Thread(target=self.monitor_workers).start()
def worker_task(self, keyword):
"""工作线程任务"""
while not self.task_queue.empty() and self.is_running:
try:
page = self.task_queue.get_nowait()
self.log_message(f"线程 {threading.current_thread().name} 开始爬取第 {page} 页")
# 发送请求
products = self.fetch_products(keyword, page)
if products is None:
self.failed_pages.append(page)
self.log_message(f"⚠️ 第 {page} 页爬取失败")
else:
# 解析商品
for product in products:
parsed = self.parse_product(product)
if parsed:
self.results.append(parsed)
self.log_message(f"✅ 第 {page} 页完成, 获取 {len(products)} 条商品")
# 任务完成
self.task_queue.task_done()
# 请求间隔
time.sleep(REQUEST_DELAY)
except queue.Empty:
break
except Exception as e:
self.log_message(f"⚠️ 线程错误: {str(e)}")
def monitor_workers(self):
"""监视工作线程状态"""
while any(worker.is_alive() for worker in self.workers):
time.sleep(0.5)
# 所有线程完成后
self.root.after(0, self.finish_crawling)
def finish_crawling(self):
"""爬取完成后的处理"""
self.is_running = False
# 保存结果
if self.results:
keyword = self.keyword_var.get().strip()
self.save_results(keyword)
self.log_message(f"✅ 爬取完成! 共获取 {len(self.results)} 条商品数据")
else:
self.log_message("⚠️ 未获取到任何商品数据")
# 报告失败页
if self.failed_pages:
self.log_message(f"⚠️ 以下页爬取失败: {', '.join(map(str, self.failed_pages))}")
# 更新界面状态
self.start_btn.config(state=tk.NORMAL)
self.stop_btn.config(state=tk.DISABLED)
self.status_var.set("就绪")
def stop_crawling(self):
"""停止爬取"""
self.is_running = False
self.log_message("⏹ 正在停止爬取...")
self.status_var.set("正在停止...")
def fetch_products(self, keyword, page):
"""获取商品数据"""
try:
# 生成签名和请求参数
sign, timestamp, request_data = self.generate_sign(page, keyword)
# 构建请求头
headers = {
"cookie": self.cookie,
"origin": "https://www.goofish.com",
"referer": "https://www.goofish.com/",
"user-agent": USER_AGENT
}
# 构建请求参数
params = {
"jsv": "2.7.2",
"appKey": APP_KEY,
"t": timestamp,
"sign": sign,
"v": "1.0",
"type": "originaljson",
"accountSite": "xianyu",
"dataType": "json",
"timeout": "20000",
"api": "mtop.taobao.idlemtopsearch.pc.search",
"sessionOption": "AutoLoginOnly",
"spm_cnt": "a21ybx.search.0.0",
"spm_pre": "a21ybx.home.searchSuggest.1.4c053da64Wswaf",
"log_id": "4c053da64Wswaf"
}
# 发送POST请求
response = requests.post(
url=API_URL,
headers=headers,
params=params,
data={"data": request_data},
timeout=15
)
# 检查响应状态
response.raise_for_status()
# 检查是否Token失效
result = response.json()
if "ret" in result and "FAIL_SYS_TOKEN_EXOIRED" in result["ret"][0]:
self.log_message("❌ Token已过期,请更新Cookie")
self.root.after(0, self.handle_token_expired)
return None
# 检查返回数据是否包含商品列表
if "data" in result and "resultList" in result["data"]:
return result["data"]["resultList"]
else:
self.log_message(f"❌ 第{page}页数据格式异常")
return None
except requests.exceptions.RequestException as e:
self.log_message(f"❌ 第{page}页请求失败: {str(e)}")
return None
except Exception as e:
self.log_message(f"❌ 第{page}页数据处理错误: {str(e)}")
return None
def handle_token_expired(self):
"""处理Token过期"""
self.stop_crawling()
messagebox.showwarning("Cookie失效", "您的Cookie已过期,请更新Cookie后重试")
def generate_sign(self, page, keyword):
"""生成签名"""
# 生成当前时间戳(毫秒级)
timestamp = int(time.time() * 1000)
# 构建请求数据
request_data = (
f'{{"pageNumber":{page},"keyword":"{keyword}","fromFilter":false,'
f'"rowsPerPage":30,"sortValue":"","sortField":"","customDistance":"",'
f'"gps":"","propValueStr":"","customGps":"","searchReqFromPage":"pcSearch",'
f'"extraFilterValue":"","userPositionJson":""}}'
)
# 构建签名原始字符串
sign_str = f"{self.token}&{timestamp}&{APP_KEY}&{request_data}"
# 计算MD5签名
md5 = hashlib.md5()
md5.update(sign_str.encode("utf-8"))
sign = md5.hexdigest()
return sign, timestamp, request_data
def parse_product(self, product):
"""解析商品数据(包含图片URL提取)"""
try:
# 从原始数据中提取核心字段
item_data = product["data"]["item"]["main"]["exContent"]
click_params = product["data"]["item"]["main"]["clickParam"]["args"]
# 提取图片URL
pic_url = item_data.get("picUrl", "")
if not pic_url:
pic_url = click_params.get("picUrl", "无图片链接")
# 提取用户昵称
user_name = item_data.get("userNick", "未知用户").strip()
# 提取标题和包邮信息
title = item_data.get("title", "").strip()
post_fee = click_params.get("tagname", "不包邮")
description = f"{post_fee} +++ {title}"
# 提取商品链接
item_id = item_data.get("itemId", "")
product_url = f"https://www.goofish.com/item?id={item_id}"
# 提取价格和地区
price = click_params.get("price", "未知")
area = item_data.get("area", "未知地区").strip()
return {
"user_name": user_name,
"description": description,
"url": product_url,
"price": price,
"area": area,
"pic_url": pic_url, # 新增图片URL字段
"item_id": item_id # 新增商品ID用于图片命名
}
except Exception as e:
self.log_message(f"⚠️ 商品数据解析异常: {str(e)}")
return None
def download_image(self, pic_url, item_id):
"""下载图片到本地,支持格式过滤和转换"""
try:
# 1. 跳过无图片链接的情况
if pic_url == "无图片链接":
return None
# 2. 处理URL中的特殊字符,补全协议头
if not pic_url.startswith(('http://', 'https://')):
pic_url = f"http:{pic_url}" if pic_url.startswith('//') else f"https://{pic_url}"
# 3. 提取并验证文件后缀
file_ext = pic_url.split(".")[-1].split("?")[0].lower()
# 处理不支持的格式(如.mpo)
if file_ext not in SUPPORTED_IMAGE_FORMATS:
self.log_message(f"⚠️ 检测到不支持的图片格式: {file_ext},将自动转换为jpg")
file_ext = "jpg" # 强制使用支持的格式
# 4. 图片文件名:用item_id避免重复
file_name = f"{IMAGE_FOLDER}/{item_id}.{file_ext}"
# 已下载则直接返回路径
if os.path.exists(file_name):
return file_name
# 5. 发送请求下载图片
headers = {"User-Agent": USER_AGENT}
response = requests.get(pic_url, headers=headers, timeout=10)
response.raise_for_status()
# 6. 保存图片到本地
with open(file_name, "wb") as f:
f.write(response.content)
# 7. 尝试转换特殊格式图片为jpg(如果是从mpo等格式转换而来)
if file_ext == "jpg" and pic_url.lower().endswith(('mpo', 'mpo?')):
try:
from PIL import Image as PILImage
# 打开图片并转换为RGB模式(兼容jpg)
img = PILImage.open(file_name)
rgb_img = img.convert('RGB')
# 覆盖保存为jpg
rgb_img.save(file_name)
self.log_message(f"✅ 特殊图片格式已成功转换为jpg: {item_id}.jpg")
except Exception as e:
self.log_message(f"⚠️ 图片格式转换失败: {str(e)},使用原始文件")
return file_name
except Exception as e:
self.log_message(f"⚠️ 图片下载失败({pic_url}): {str(e)}")
return None
def save_results(self, keyword):
"""保存结果到Excel(包含图片插入)"""
try:
# 创建Excel工作簿和工作表
wb = Workbook()
ws = wb.active
# 添加表头(包含图片列)
ws.append(["用户名字", "简介", "链接", "价格", "地区", "图片"])
# 调整列宽
ws.column_dimensions["A"].width = 15 # 用户名
ws.column_dimensions["B"].width = 40 # 简介
ws.column_dimensions["C"].width = 30 # 链接
ws.column_dimensions["F"].width = 20 # 图片列
# 写入数据
for row_idx, data in enumerate(self.results, start=2): # 从第2行开始(跳过表头)
# 写入文字信息
ws.cell(row=row_idx, column=1, value=data["user_name"])
ws.cell(row=row_idx, column=2, value=data["description"])
ws.cell(row=row_idx, column=3, value=data["url"])
ws.cell(row=row_idx, column=4, value=data["price"])
ws.cell(row=row_idx, column=5, value=data["area"])
# 下载并插入图片
pic_path = self.download_image(data["pic_url"], data["item_id"])
if pic_path and os.path.exists(pic_path):
try:
# 插入图片
img = Image(pic_path)
# 调整图片大小
img.width = 100
img.height = 100
# 插入到F列当前行
ws.add_image(img, anchor=f"F{row_idx}")
# 调整行高以适应图片
ws.row_dimensions[row_idx].height = 80
except Exception as e:
self.log_message(f"⚠️ 图片插入失败({pic_path}): {str(e)}")
# 生成文件名
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"{keyword}_{timestamp}.xlsx"
wb.save(filename)
self.log_message(f"✅ 数据已保存到 {filename}(含图片)")
except Exception as e:
self.log_message(f"❌ 保存Excel文件失败: {str(e)}")
def main():
root = tk.Tk()
app = XianyuSpiderGUI(root)
root.mainloop()
if __name__ == "__main__":
main()![图片[1]-如何高效获取咸鱼商品:省钱秘籍与购物技巧](https://www.zywz6.com/wp-content/uploads/2025/07/d2b5ca33bd20250725131123-1024x602.png)
![图片[2]-如何高效获取咸鱼商品:省钱秘籍与购物技巧](https://www.zywz6.com/wp-content/uploads/2025/07/d2b5ca33bd20250725131142-1024x506.png)
© 版权声明
THE END


 会员专属
会员专属